Zone Ai 更换模型教程
更换 ONNX、构建 TensorRT engine、切换正式模型并检查类别和参数。
本文用于指导用户在副机推理端更换识别模型,并完成 TensorRT Engine 构建、模型切换、目标类别检查和参数预设导入。
适用场景
当需要切换不同游戏、不同识别版本或不同目标类别模型时,需要按本文流程操作。
常见场景包括:
- 从当前模型切换到新的游戏模型。
- 更新同一游戏的新版本模型。
- 新副机首次部署后,需要根据本机显卡生成专用 Engine。
- 更换模型后,目标类别、瞄准位置或参数预设需要重新确认。
模型文件类型
Zone Ai 推理端常见模型文件分为两类:
| 类型 | 后缀 | 用途 | 是否可以分发 |
|---|---|---|---|
| 原始模型 | .onnx | 通用模型文件,用于生成当前副机可用的 Engine | 可以 |
| TensorRT Engine | .engine | 针对当前副机显卡和运行环境生成的高性能推理文件 | 不建议跨机器分发 |
.onnx 是模型的通用格式。它可以放入模型目录,由推理端根据当前副机的显卡、驱动、CUDA / TensorRT 环境生成 .engine 文件。
.engine 是针对当前机器生成的 TensorRT 推理文件。不同副机、不同显卡、不同驱动或不同 TensorRT 环境生成的 Engine 不一定通用。即使显卡型号相同,也建议每台副机单独生成。
重要规则
更换模型前先记住以下规则:
- 不要把一台副机生成的
.engine直接复制给另一台副机使用。 - 分发模型时优先分发
.onnx,让用户现场生成.engine。 - 更换模型后,需要检查目标类别是否正确。
- 更换模型后,需要使用与该模型配套的参数预设。
- 如果模型目录里已经存在对应
.engine,软件通常不会重复生成。 - 如果只有
.onnx,保存模型选择并重启后,软件会开始生成对应.engine。
操作前准备
操作前请确认:
- 副机推理端
Ai.exe可以正常启动。 - NVIDIA 环境包已经正确部署。
- 新模型文件已经下载完成。
- 如果有配套参数预设,请一并下载。
- 当前正在运行的
Ai.exe已关闭。
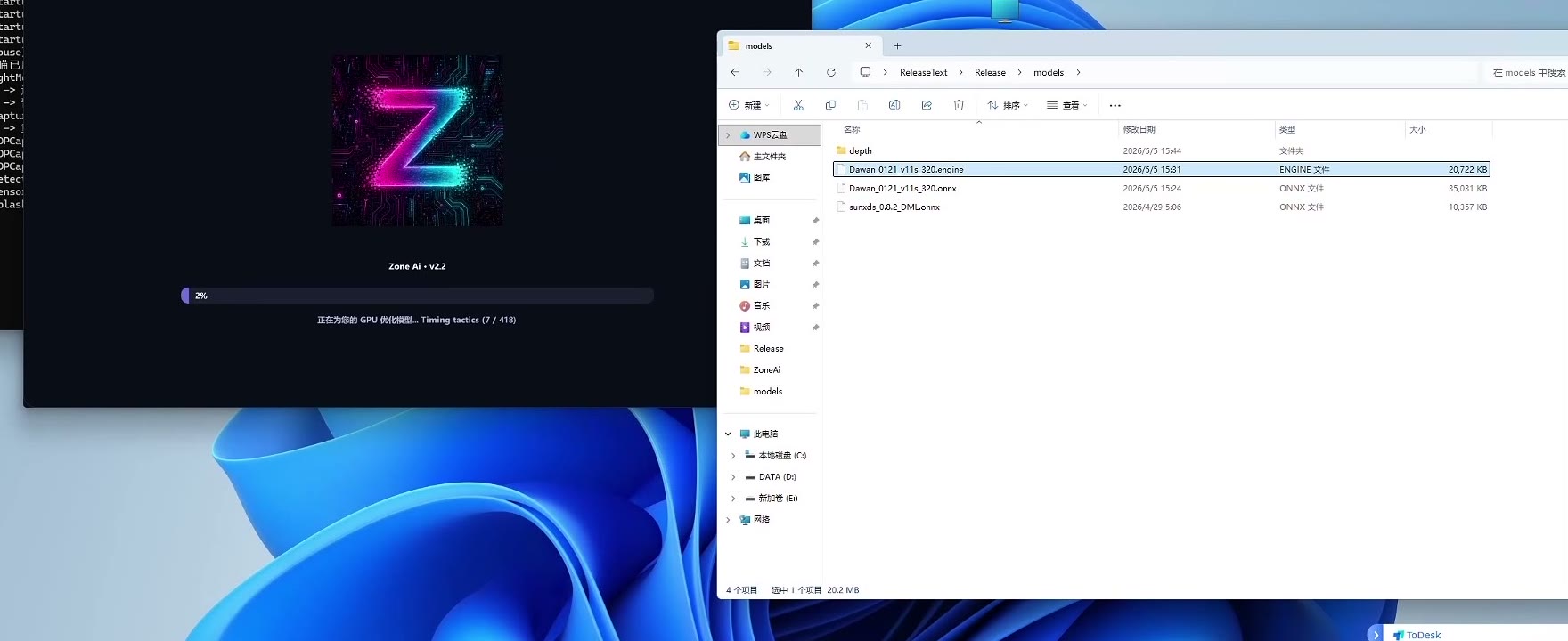
第一步:放入 ONNX 模型
打开副机推理端所在目录,找到模型目录。
通常模型目录为:
models将新的 .onnx 模型复制到该目录下。
如果目录中已有旧模型,可以保留;多个模型可以同时放在模型目录中,后续在软件内选择需要使用的模型即可。
第二步:选择 ONNX 模型并保存
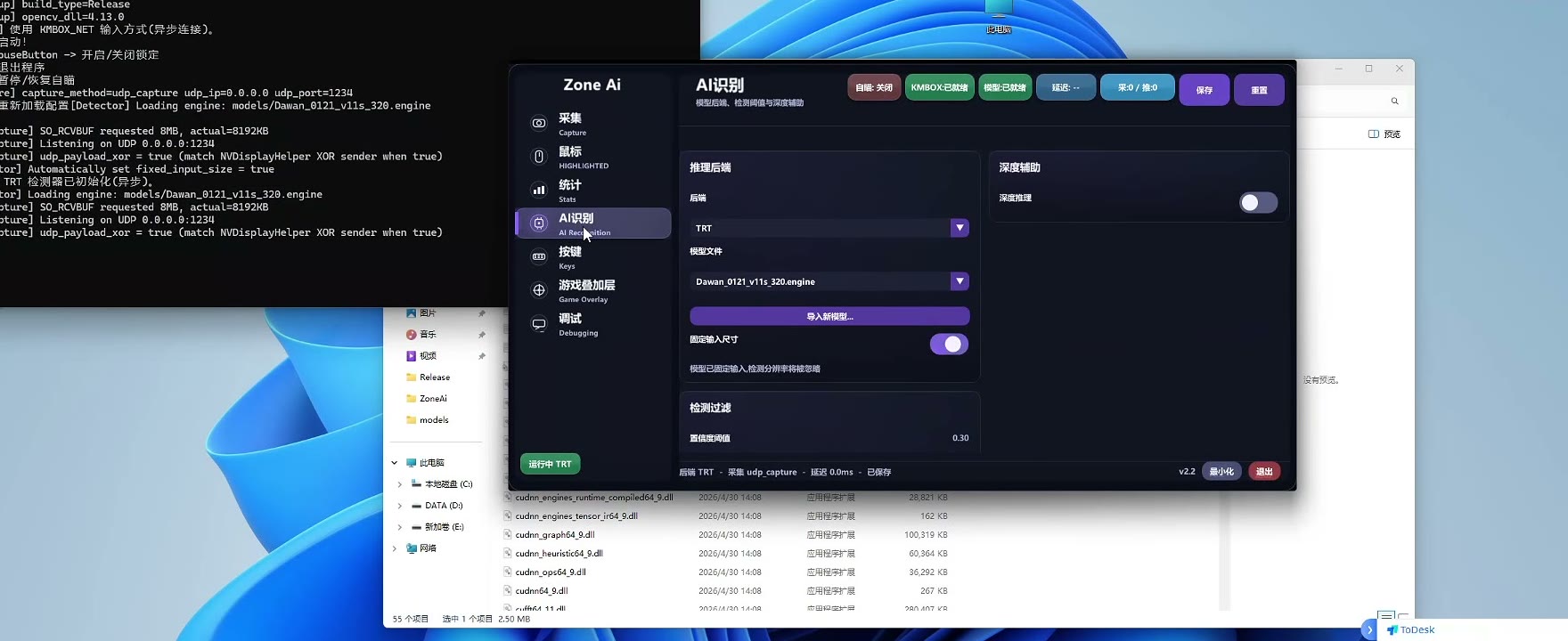
启动 Ai.exe。
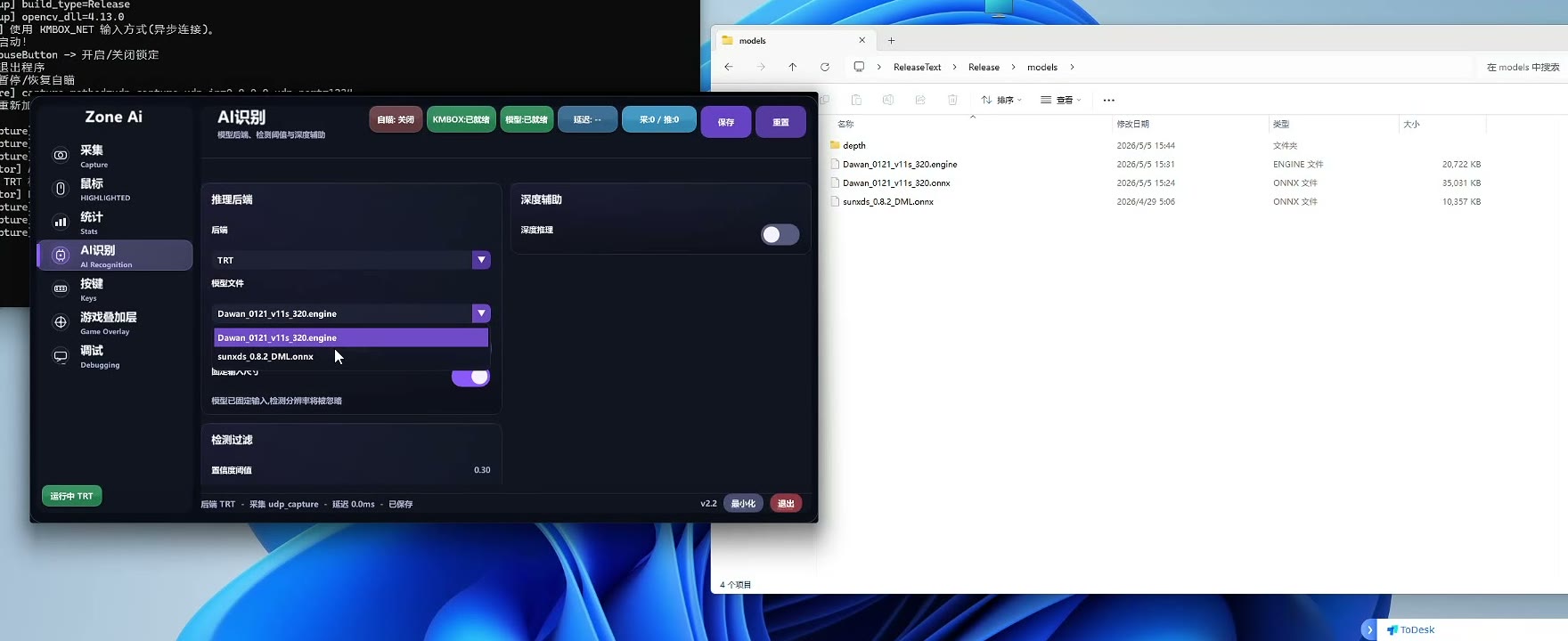
进入模型或识别相关设置区域,在模型下拉框中选择刚刚放入的 .onnx 模型。
选择后点击保存配置。
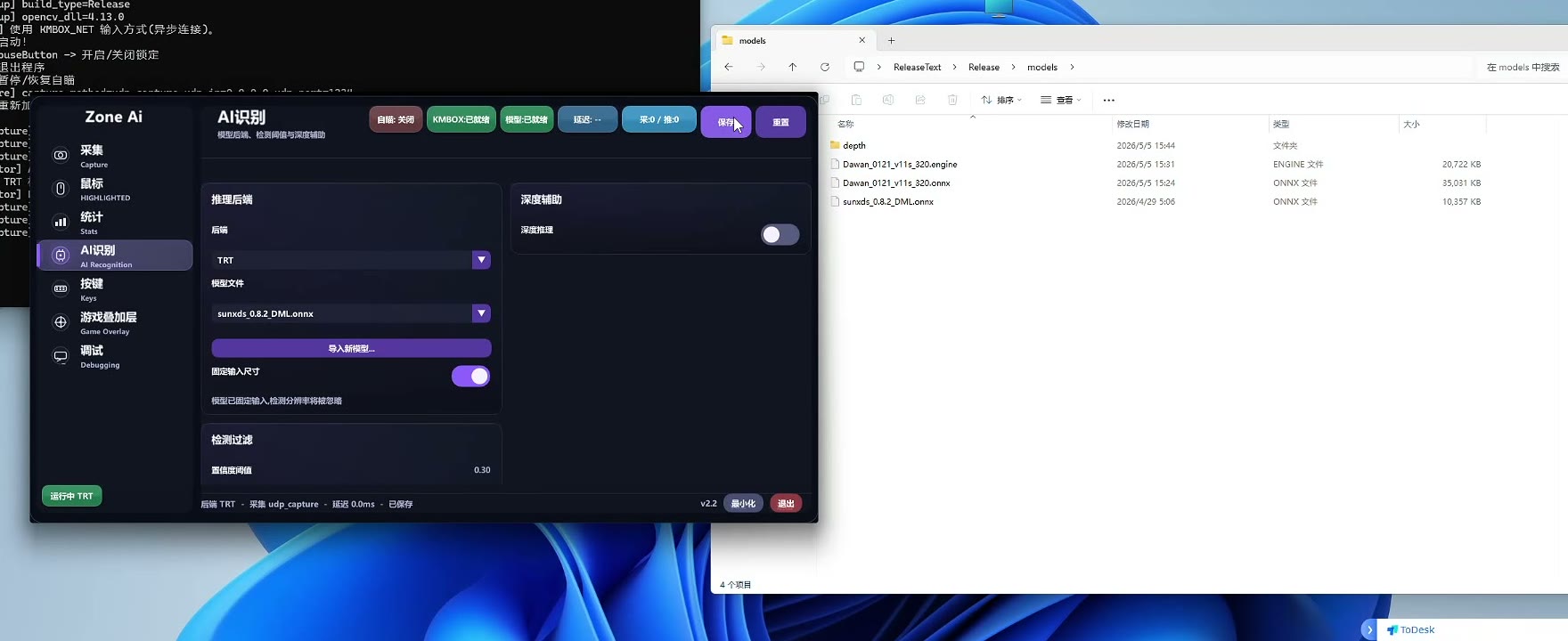
保存完成后,关闭 Ai.exe。
第三步:重启并生成 Engine
重新启动 Ai.exe。
软件会根据当前副机的显卡和运行环境,将 .onnx 模型转换为对应的 .engine 文件。
构建过程可能需要等待一段时间,时间长短取决于显卡性能、模型大小和当前环境。
构建期间不要关闭软件,也不要移动模型文件。
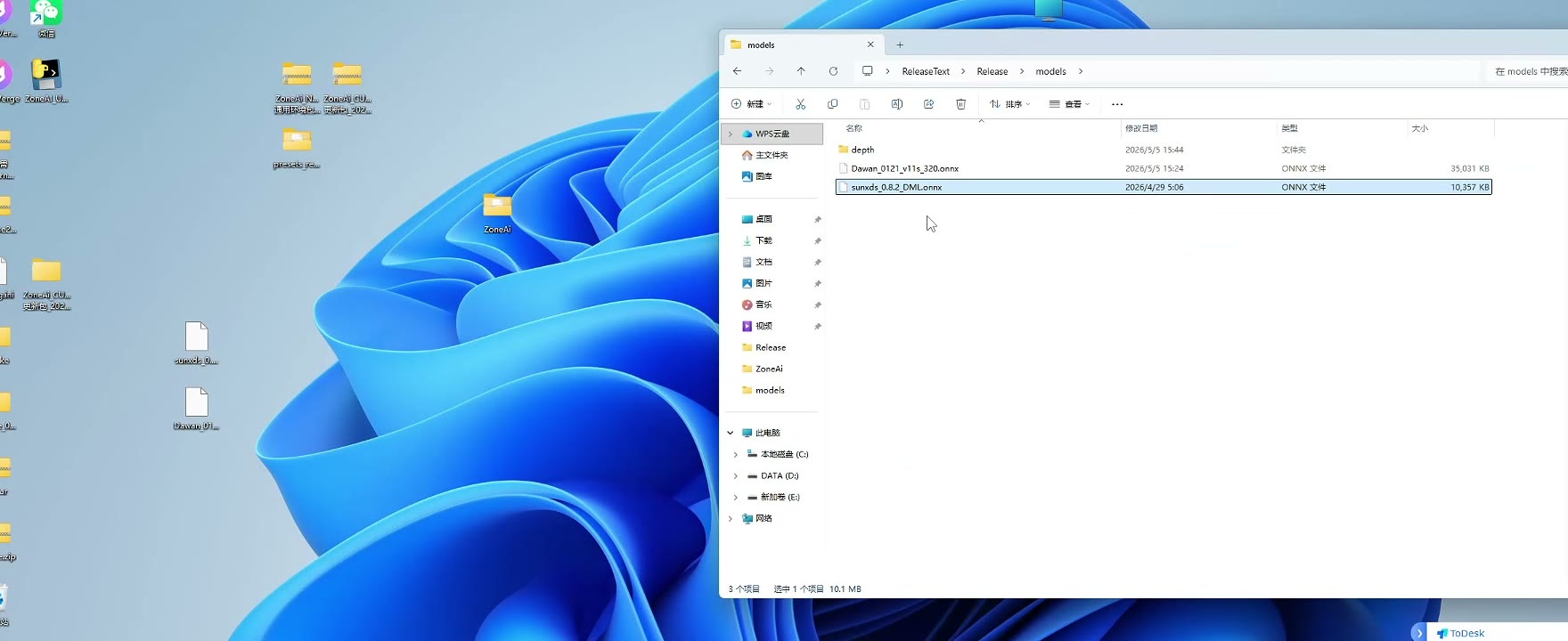
第四步:切换到 Engine 模型
Engine 生成完成后,重新进入模型选择位置。
此时模型列表中应能看到对应的 .engine 文件。
选择新生成的 .engine 模型,并保存配置。
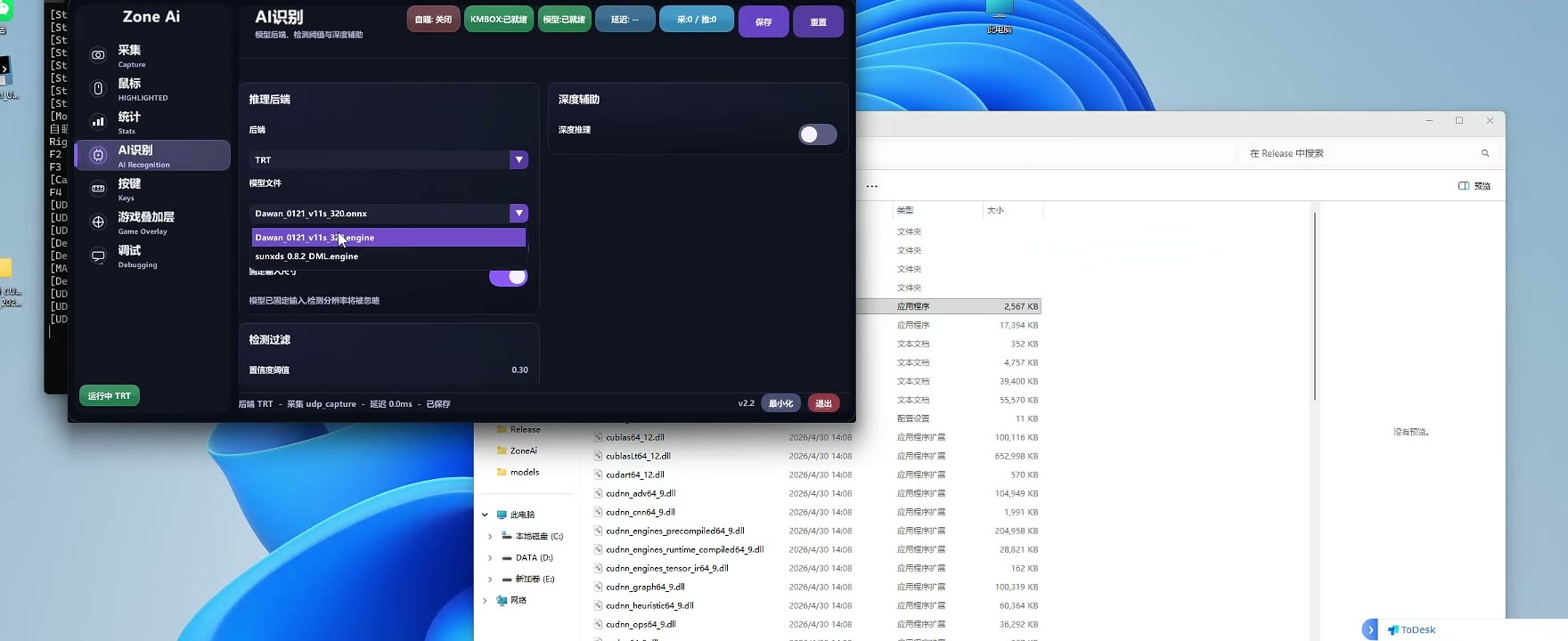
后续正式运行时应使用 .engine 模型,而不是继续停留在 .onnx 模型上。
第五步:检查目标类别
不同模型的目标类别可能不一样。更换模型后,必须检查目标类别。
常见类别可能包括:
- 敌人身体
- 敌人头部
- 队友
- 小兵
- 倒地目标
- 靶场身体
- 靶场头部
类别 ID 的含义取决于模型训练时的标注方式。不同模型之间不能默认共用同一套类别解释。
如果旧模型只有 ID0、ID1,新模型有更多类别,需要按新模型的类别说明重新设置。
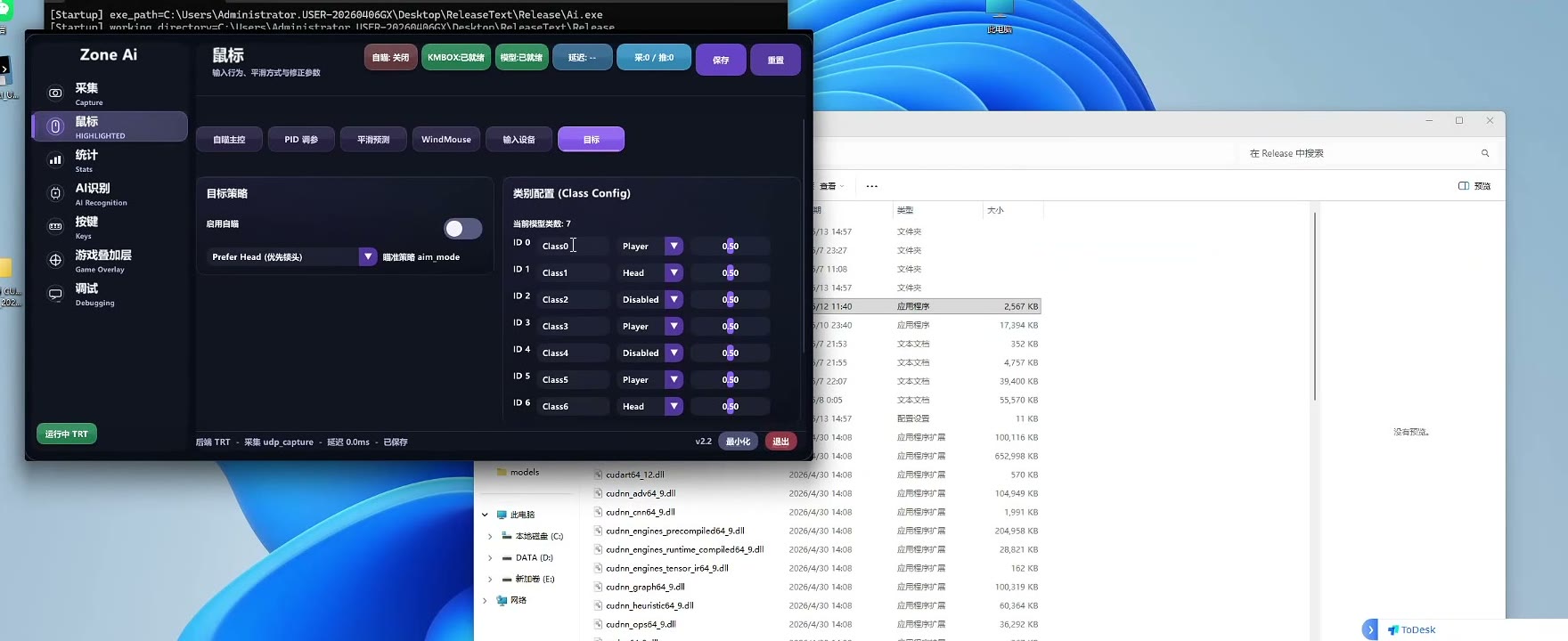
第六步:检查瞄准位置
目标类别旁边的数值通常用于控制该类别的瞄准位置。
例如身体类别可以设置为瞄准身体中部、胸口或更高位置。不同模型、不同游戏和不同目标框标注方式,适合的数值会不同。
建议优先使用模型配套参数预设,不要直接沿用旧模型的目标类别和瞄准位置。
第七步:导入配套参数预设
如果模型提供了配套参数预设,请按以下方式导入:
- 打开配套参数预设文件。
- 全选并复制预设内容。
- 打开推理端当前使用的配置文件。
- 将预设内容粘贴到对应配置中。
- 保存配置文件。
- 重新启动
Ai.exe,或在软件内重新加载配置。
导入参数后,再根据现场环境微调采集、推流、目标类别、PID 或鼠标输出相关参数。
多模型使用建议
如果用户需要同时使用多个游戏模型,可以把多个 .onnx 模型放在模型目录中。
每个 .onnx 都需要在当前副机上生成自己的 .engine。
切换游戏时,需要同时确认三件事:
- 当前选择的模型是否正确。
- 当前目标类别是否与模型匹配。
- 当前参数预设是否与游戏和模型匹配。
只切换模型、不切换参数预设,可能导致识别目标正确但瞄准效果异常。
常见问题
为什么不能直接发 Engine?
.engine 与生成它的显卡、驱动、CUDA、TensorRT 和运行环境有关。跨机器使用可能无法加载、推理异常或性能不稳定。
标准做法是分发 .onnx,让每台副机现场生成自己的 .engine。
为什么选择 ONNX 后还要重启?
保存 .onnx 模型选择后,重启可以让推理端进入 Engine 构建流程,并生成当前副机可用的 .engine 文件。
为什么生成 Engine 后还要再切换一次?
.onnx 是用于生成 Engine 的模型文件。正式运行时应选择生成后的 .engine,这样才能使用 TensorRT 加速推理。
更换模型后为什么目标类别不一样?
类别由模型训练时的标注决定。不同模型的类别数量和类别含义可能不同,所以更换模型后必须重新检查类别。
更换模型后效果不对怎么办?
优先检查以下内容:
- 是否已经选择
.engine,而不是.onnx。 - 是否导入了该模型配套参数。
- 目标类别是否选择正确。
- 瞄准位置数值是否符合当前模型。
- 采集和 UDP 推流是否正常。
- 副机显卡环境是否完整。
推荐流程速查
关闭 Ai.exe
复制 .onnx 到 models
启动 Ai.exe
选择 .onnx
保存配置
关闭 Ai.exe
重新启动并等待生成 .engine
选择 .engine
保存配置
检查目标类别
导入配套参数预设
测试识别和瞄准效果